AI in Security Operation Centers (SOC)s
- brencronin
- Nov 4, 2025
- 7 min read
Updated: Apr 12
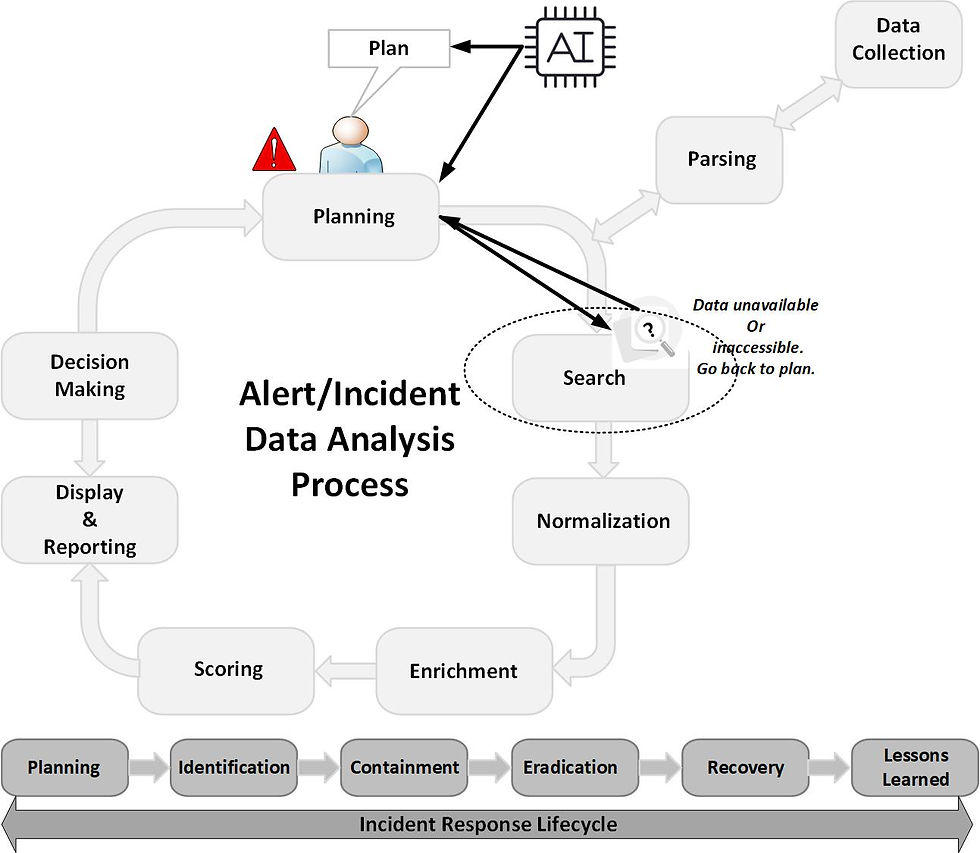
Standard IR Data Analysis phases
A practical way to evaluate AI’s impact on incident response (IR) is by examining how it enhances the data analysis phases that analysts perform during alert triage and incident handling. These are analytical stages, distinct from the traditional IR lifecycle of Identification, Containment, Eradication, Recovery, and Lessons Learned.
The core data analysis phases include: Planning, Search (including Data Collection and Parsing), Normalization, Enrichment, Scoring, Display and Reporting, and Decision Making. Adapted from Brian Carrier ('AI in Digital Investigations' Cyber Triage).

Two important considerations:
These processes are iterative. For instance, challenges identified during data collection impact search options so may lead to refinements in planning, just as insights gained during reporting or decision-making can reshape earlier phases.
These processes are rarely codified. Most organizations have limited formalization of these data analysis steps, leaving significant room for AI to introduce structure, consistency, and efficiency.
Data Analysis Phases – Planning
Data Analysis Phases – Planning
Every investigation begins with defining the key questions and identifying what data is required, where it resides, and how it should be collected. Traditionally, this process has been manual and time-consuming. AI can accelerate it by generating hypotheses, recommending investigative paths, and dynamically adjusting plans as new evidence or constraints emerge. Effective hypotheses should be both traceable and explainable, traceable by referencing original data sources (e.g., files, executed commands) for verification, and explainable by providing context on why a particular hypothesis was generated, allowing investigators to evaluate it with greater confidence.

Important Note for IR Planning
While the integration of artificial intelligence introduces significant potential for creativity and adaptability in response planning, it also carries the risk of non-deterministic outcomes, wherein similar incidents may yield divergent response plans. Such variability can have downstream implications in operational environments that prioritize standardization and repeatability, both of which are essential for achieving consistent results and enabling the quantitative assessment of response effectiveness. In the absence of repeatable processes, the ability to perform reliable measurement and derive actionable insights from those measurements is substantially diminished.
Data Analysis Phases – Data Search (including Data Collection & Parsing)
This phase involves gathering data from relevant systems, whether through direct artifact extraction or querying data silos such as EDR, SIEM, or cloud logs. Automation improves consistency and scale, while AI can help prioritize which data sources are most likely to yield actionable results. Once collected, data must be converted into a usable format. Historically, this relied on static parsers with predefined rules. AI-assisted parsing, however, can dynamically adapt to evolving log formats, new data structures, and even obfuscated data, improving accuracy and flexibility in data processing.
There are two important dynamics to highlight here, which also illustrate subtle differences between Incident Response (IR) and digital forensics (DF) investigations.
In incident response, analysts typically work with data that is already being collected and parsed on an ongoing basis, such as logs, telemetry, and outputs from instrumentation like EDR systems. This enables rapid analysis and correlation using pre-existing data streams.
In contrast, digital forensics investigations often require accessing unique, system-specific data that must be collected in a targeted manner to test or support a hypothesis. This data is not usually captured continuously due to instrumentation limits, storage costs, or feasibility concerns. As a result, DF efforts often begin with a tailored data acquisition and parsing process before analysis can occur.
While these distinctions are common, they are not absolute. DF investigations may leverage data that has been continuously collected, just as IR investigations may require ad hoc collection of data that was not part of routine telemetry or logging efforts.
This distinction underscores why data collection and parsing are represented as a separate phase positioned between planning and search.

It is also worth noting that investigation planning is often shaped by the data available for analysis. In many cases, an analyst develops a plan to test a specific hypothesis, only to discover that the required data is unavailable or difficult to access. This limitation frequently necessitates revising the investigation plan to align with the data that is actually available.
Data Analysis Phases – Normalization
In investigations, normalization is a broad process focused on adding structure and meaning to raw data. This involves converting unstructured or semi-structured data into standardized formats, such as mapping values to entities like IP addresses, URLs, or file hashes, and creating meaningful representations, for example, interpreting a binary execution as a “process.” Normalization also includes reducing redundancy and deriving higher-level meaning from complex evidence objects such as scripts or command sequences.
Traditional tools often struggle with these tasks, particularly when data originates from diverse or non-standard sources. AI technologies show strong potential to enhance normalization by enabling contextual mapping, semantic interpretation, and cross-dataset disambiguation, thereby improving the accuracy and efficiency of investigative analysis.

Data Analysis Phases – Enrichment
During enrichment, artifacts are augmented with additional intelligence or contextual information, such as hash lookups, object recognition, vulnerability data, or even language translations. Historically, enrichment has been the core use case for Security Orchestration, Automation, and Response (SOAR) systems. In this process, the SOAR tool takes an entity from an alert, such as an IP address, file hash, or domain, and queries an external source like a Cyber Threat Intelligence (CTI) platform, returning the results to the analyst for further context. Over time, EDR and SIEM platforms have absorbed much of this functionality natively, reducing reliance on external SOAR tools, though these still retain value in certain 3rd party enrichments and other complex or multi-vendor environments.

Data Analysis Phases – Scoring
Scoring, has traditionally been a manual process, whether assigning an initial alert or incident severity (e.g., low, medium, high, or critical) or interpreting the significance of specific indicators observed during an investigation. Early attempts at automating scoring, before the rise of AI, relied on static rule sets and manually assigned values integrated into logging systems. For example, a system might increase an alert’s priority if the suspicious event occurred on a host with a critical vulnerability or on a system tagged as mission-critical. Over time, machine learning models began to augment this process. Instead of relying solely on static thresholds, these models assessed event relationships, frequency patterns, and historical analyst feedback (such as prior false-positive tagging) to adjust scores dynamically.
Building upon the relationship between a vulnerability and its associated incident, AI enhances the ability to correlate and integrate disparate data sources related to an alert by leveraging key attributes such as asset identifiers and user identities. This correlated data may include known vulnerabilities, exposure information, and threat intelligence indicators derived from cyber threat intelligence (CTI) sources.
Moreover, AI introduces significant value in this phase by enabling the interpretation of patterns and artifacts that were previously random or obscure. As highlighted in the enrichment stage, AI’s contextual understanding allows these elements to be analyzed with greater precision and meaning. When this enriched insight is fed back into the model, it enhances the accuracy and contextual relevance of scoring, thereby improving the overall quality of incident prioritization and analysis.

Caution is warranted. AI-driven scoring can suffer from non-determinism, meaning the same input may not always produce the same result. Additionally, sycophancy bias, where the model tailors its response toward perceived expectations, can distort relevance scoring (for example, weighting data as “high relevance” simply because that seems preferred). These factors must be carefully managed to maintain consistency and reliability in AI-assisted analysis.
Data Analysis Phases – Display & Reporting
Data presentation is critical for human understanding. Display & Reporting, has traditionally been a largely manual process unless supported by built-in visualization components within detection tools such as EDR platforms. Examples include device timelines, which present system activity organized by categories like network, registry, and process events, and incident graphs, which visualize relationships between entities (e.g., showing that a specific IP address connected to a particular host). The generation of reports involves documenting key findings, response actions, and attribution in a structured format. This, too, has been a manual and time-consuming process where AI can add significant value by automating report generation and summarization. Enhancing this capability further, such as by making these AI-generated summaries accessible via APIs, would allow seamless integration with ticketing systems, dashboards, and case management tools, driving real-time reporting efficiency.

Data Analysis Phases – Decision Making
The final phase focuses on documenting findings and determining the next steps. Importantly, AI-driven decision support should connect recommendations back to the initial investigative plan and include a “refute analysis”, testing both supporting and opposing hypotheses. This mirrors the scientific method, ensuring that conclusions are evidence-based, balanced, and transparent.

What's in Store for the Future?
The Software Analysis Cyber Research organization published a 2025 report titles, 'SACR AI SOC Market Landscape For 2025', that is a comprehensive view of the 2025 AI SOC market detailing emerging trends within security. In this report they define the vendor landscape into four defined categories:
AI-powered XDR co-pilots
Automated Tier-1 alert analysts
Advanced AI-driven threat hunting platforms
Workflow-centric AI automation engineers
From jack Nagieri Detection at Scale. 'The State of AI in Security Operations: 5 Patterns That Defined 2025'. "As we navigate this exciting technological shift, a few patterns have become clear:
Context engineering is the key to effective agents
Agent accuracy is preferred over speed, but both are critical
Data privacy is table stakes for commercial AI solutions
Autonomy with human-in-the-loop balances productivity with safety
Focused agents are preferred for specialized security workflows"
References
Evaluating AI Agents in Security Operations
Evaluating AI Agents in Security Operations (December 2025)
SACR AI SOC Market Landscape For 2025
2025 Wrapped: Essential Reading on AI in Security Operations
Why Agentic AI Startups Will Struggle Against Cybersecurity Incumbents
Decoupled SIEM: Where I Think We Are Now?
Understanding Semantic Layers in Security Operations
Measuring ROI of AI agents in security operations
Automate Smarter, Not Louder: Using Interactive AI Feedback Loops
The State of AI in Security Operations: 5 Patterns That Defined 2025
AI Research in Security Operation
https://www.cotool.ai/research?utm_source=det-eng-weekly&utm_medium=newsletter&utm_campaign=research
When Marketing Fails: AI SOC and the curious gap between vendor claims and user experience

Comments